
How to Write a Query with a Regular Expression in Painless
A note to future me, since I keep forgetting — maybe it’s also useful for others — on how to write:
- a regular expression (or regex)
- in Elasticsearch’s Painless scripting language
- in a query through
runtime_mappings
Example dataset: Extract the top- and second-level domain from a string with subdomains. So how to get cnn.com from weather.cnn.com, for example.
Regular Expression #
A tool like regex101.com will make this easier, but plenty of alternatives exist.
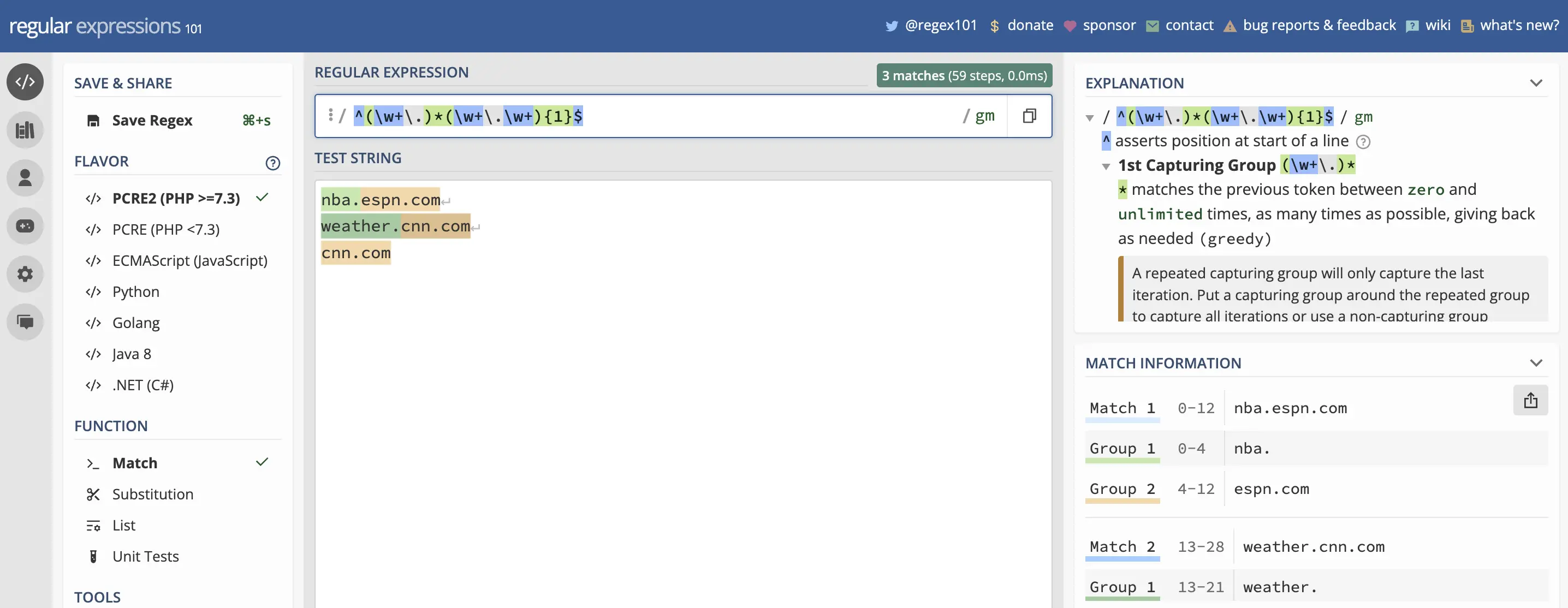
A working regular expression would be ^([\w\-]+\.)*([\w\-]+\.\w+){1}$ (without going into further tweaks):
^must match from the start of the string.(...)capture everything enclosed and be able to reference it by ID (starting at 1).[...]for a group of characters.\wfor any word character.\-for a dash (which needs to be escaped).+one or more of it.\.a dot (which needs to be escaped).*zero or more of it.{1}with exactly one occurrence.$the string must end here.
Runtime Mapping #
Before running the query, a quick test dataset:
PUT test/_doc/1
{
"name": "nba.espn.com"
}
PUT test/_doc/2
{
"name": "weather.CNN.com"
}
PUT test/_doc/3
{
"name": "cnn.com"
}
PUT test/_doc/4
{
"name": "wrong"
}
PUT test/_doc/5
{
"no-name": "cnn.com"
}
PUT test/_doc/6
{
"name": "some.more.sub-d0mains.com"
}
And then the query:
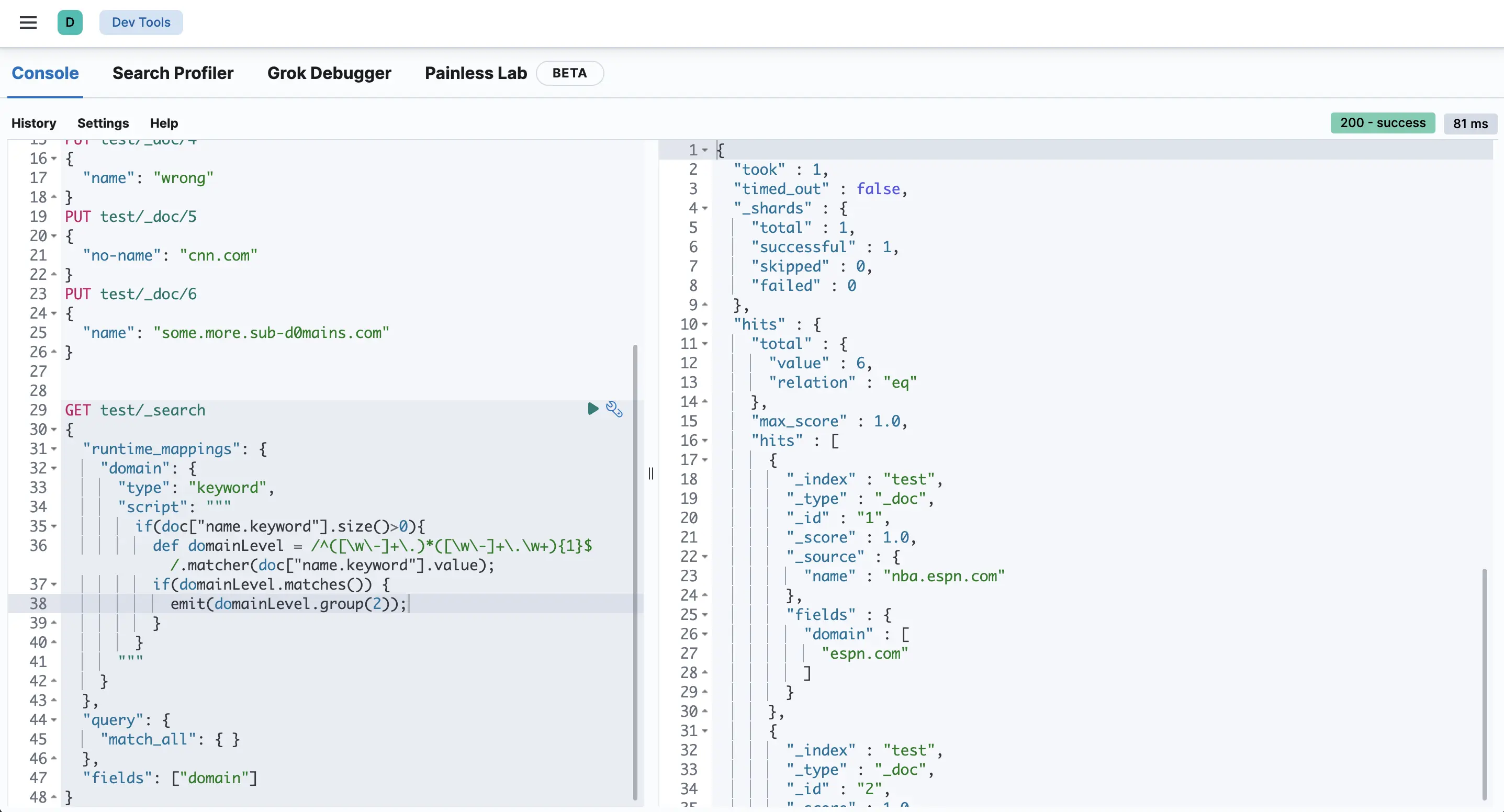
GET test/_search
{
"runtime_mappings": {
"domain": {
"type": "keyword",
"script": """
if(doc["name.keyword"].size()>0){
def domainLevel = /^([\w\-]+\.)*([\w\-]+\.\w+){1}$/.matcher(doc["name.keyword"].value);
if(domainLevel.matches()) {
emit(domainLevel.group(2));
}
}
"""
}
},
"query": {
"match_all": { }
},
"fields": ["domain"]
}
The most important parts:
"runtime_mappings"to add the Painless script at query time."domain"is the name of the newly created runtime field."type": "keyword"and its data type.if(doc["name.keyword"].size()>0)being on the safe side that the field exists./^([\w\-]+\.)*([\w\-]+\.\w+){1}$/the unquoted regular expression between forward slashes..matcher(doc["name.keyword"].valuematching on the value of the indexedkeyword(rather than atextfield).if(domainLevel.matches())if there is a match.emit(domainLevel.group(2))emitting the second group of the matched regular expression."match_all"searching across all documents."fields": ["domain"]explicitly includes the extracted runtime field in the search results, which wouldn’t be the case otherwise.
The result (shortened for easier readability) is then:
{
"_source" : {
"name" : "nba.espn.com"
},
"fields" : {
"domain" : [
"espn.com"
]
}
},
{
"_source" : {
"name" : "weather.CNN.com"
},
"fields" : {
"domain" : [
"CNN.com"
]
}
},
{
"_source" : {
"name" : "cnn.com"
},
"fields" : {
"domain" : [
"cnn.com"
]
}
},
{
"_source" : {
"name" : "wrong"
}
},
{
"_source" : {
"no-name" : "cnn.com"
}
},
{
"_source" : {
"name" : "some.more.sub-d0mains.com"
},
"fields" : {
"domain" : [
"sub-d0mains.com"
]
}
}
PS: Remember, the plural of regex is regret. Use with caution 🫠